 Home-theater-designers
Home-theater-designers
Adatelemzőként gyakran szembesül azzal, hogy több adatkészletet kell kombinálni. Ezt meg kell tennie, hogy befejezze az elemzést, és következtetésre jusson vállalkozása/érdekelt felei számára.
Gyakran kihívást jelent az adatok megjelenítése, ha azokat különböző táblákban tárolják. Ilyen körülmények között a csatlakozások bizonyítják értéküket, függetlenül attól, hogy milyen programozási nyelven dolgozik.
MAKEUSEOF A NAP VIDEÓJA
A Python-illesztések olyanok, mint az SQL-illesztések: adathalmazokat egyesítenek úgy, hogy soraikat egy közös indexen egyeztetik.
Hozzon létre két DataFrame-et referenciaként
Az útmutató példáinak követéséhez két minta DataFrame-et hozhat létre. Használja a következő kódot az első DataFrame létrehozásához, amely egy azonosítót, keresztnevet és vezetéknevet tartalmaz.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)Az első lépéshez importálja a pandák könyvtár. Ezután használhat egy változót, a , a DataFrame konstruktor eredményének tárolásához. Adjon át a konstruktornak egy szótárt, amely tartalmazza a szükséges értékeket.
Végül jelenítse meg a DataFrame érték tartalmát a nyomtatási funkcióval, hogy ellenőrizze, hogy minden úgy néz ki, ahogyan azt elvárná.
Hasonlóképpen létrehozhat egy másik DataFrame-et, b , amely azonosítót és fizetési értékeket tartalmaz.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)A kimenetet konzolon vagy IDE-ben ellenőrizheti. Meg kell erősítenie a DataFrames tartalmát:
Miben különböznek a csatlakozások a Python egyesítése funkciójától?
A pandas könyvtár az egyik fő könyvtár, amellyel a DataFrame-eket manipulálhatja. Mivel a DataFrame-ek több adatkészletet tartalmaznak, a Pythonban különféle funkciók állnak rendelkezésre az összekapcsoláshoz.
A Python sok egyéb mellett az összekapcsolási és egyesítési funkciókat is kínálja, amelyek segítségével a DataFrame-eket kombinálhatja. A két funkció között éles különbség van, amelyet szem előtt kell tartania, mielőtt bármelyiket használná.
A join függvény két DataFrame-et kapcsol össze azok indexértékei alapján. Az Merge funkció egyesíti a DataFrame-eket az indexértékek és az oszlopok alapján.
Mit kell tudni a csatlakozásokról a Pythonban?
Mielőtt megvitatná az elérhető csatlakozások típusait, néhány fontos dolgot érdemes megjegyezni:
legjobb hely kiskutya beszerzésére
- Az SQL join az egyik legalapvetőbb funkció és meglehetősen hasonlóak a Python csatlakozásaihoz.
- A DataFrames-hez való csatlakozáshoz használhatja a pandas.DataFrame.join() módszer.
- Az alapértelmezett összekapcsolás bal oldali illesztést hajt végre, míg az egyesítés funkció belső összekapcsolást hajt végre.
A Python-illesztés alapértelmezett szintaxisa a következő:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Hívja meg a csatlakozási metódust az első DataFrame-en, és adja át a második DataFrame-et első paraméterként, Egyéb . A fennmaradó érvek a következők:
- tovább , amely megnevez egy indexet a csatlakozáshoz, ha egynél több van.
- hogyan , melyik meghatározza a csatlakozás típusát, beleértve a belső, külső, bal és jobb oldali csatlakozást.
- l utótag , melyik meghatározza az oszlopnév bal utótag-karakterláncát.
- rsufix , melyik meghatározza az oszlopnév jobb utótag karakterláncát.
- fajta , melyik egy logikai érték, amely azt jelzi, hogy rendezni kell-e az eredményül kapott DataFrame-et.
Tanulja meg a különböző típusú csatlakozásokat a Pythonban
A Pythonnak van néhány csatlakozási lehetősége, amelyeket az óra igényétől függően gyakorolhat. Íme a csatlakozási típusok:
1. Bal csatlakozás
A bal oldali összekapcsolás érintetlenül tartja az első DataFrame értékeit, miközben behozza a megfelelő értékeket a másodikból. Például, ha be szeretné hozni a megfelelő értékeket innen b , a következőképpen határozhatja meg:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Amikor a lekérdezés végrehajtódik, a kimenet a következő oszlophivatkozásokat tartalmazza:
- ID_left
- Fname
- Lnév
- ID_right
- Fizetés
Ez az összekapcsolás az első három oszlopot az első DataFrame-ből, az utolsó két oszlopot pedig a második DataFrame-ből húzza ki. Használta a l utótag és rsufix értékeket az ID oszlopok átnevezéséhez mindkét adatkészletből, biztosítva, hogy a kapott mezőnevek egyediek legyenek.
A kimenet a következő:
hogyan kell használni a merészséget a zenéléshez

2. Jobb csatlakozás
A jobb oldali összekapcsolás érintetlenül tartja a második DataFrame értékeit, miközben behozza az egyező értékeket az első táblából. Például, ha be szeretné hozni a megfelelő értékeket innen a , a következőképpen határozhatja meg:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)A kimenet a következő:
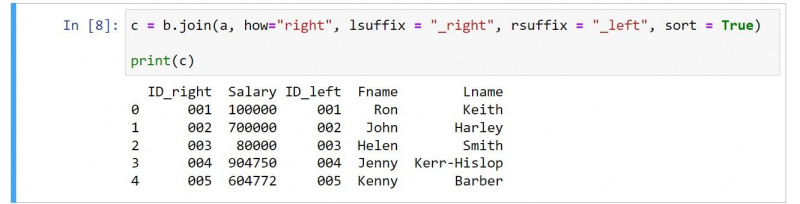
Ha átnézi a kódot, látható néhány nyilvánvaló változás. Például az eredmény tartalmazza a második DataFrame oszlopait az első DataFrame oszlopai előtt.
Használjon értéket jobb a hogyan argumentum egy jobb összekapcsolás megadásához. Figyeld meg azt is, hogyan válthatod át a l utótag és rsufix értékeket, hogy tükrözzék a megfelelő csatlakozás természetét.
A szokásos illesztéseknél előfordulhat, hogy gyakrabban használ bal, belső és külső illesztéseket, mint a jobb oldali csatlakozásnál. A felhasználás azonban teljes mértékben az Ön adatigényétől függ.
3. Belső csatlakozás
Egy belső összekapcsolás szállítja a megfelelő bejegyzéseket mindkét DataFrame-ből. Mivel az összekapcsolások az indexszámokat használják a sorok egyeztetésére, a belső összekapcsolás csak az egyező sorokat adja vissza. Ehhez az illusztrációhoz használjuk a következő két DataFrame-et:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)A kimenet a következő:
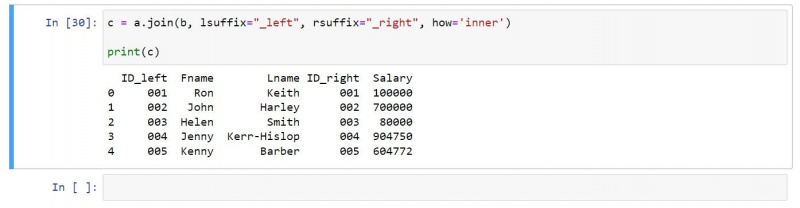
A belső csatlakozást a következőképpen használhatja:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Az eredményül kapott kimenet csak olyan sorokat tartalmaz, amelyek mindkét bemeneti DataFrame-ben léteznek:
4. Külső csatlakozás
Egy külső összekapcsolás mindkét DataFrame összes értékét visszaadja. Az egyező értékkel nem rendelkező sorok esetén az egyes cellákon null értéket állít elő.
Ugyanazt a DataFrame-et használva, mint fent, itt van a külső csatlakozás kódja:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)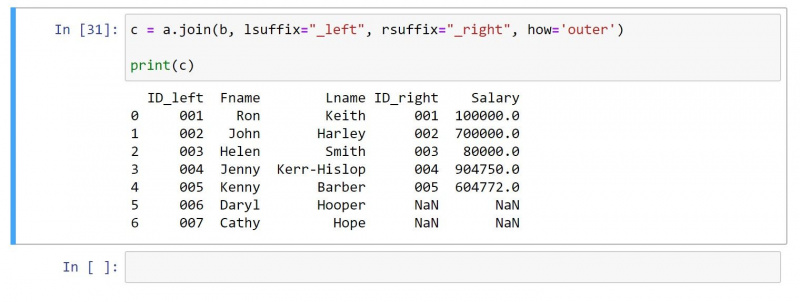
Csatlakozások használata Pythonban
Az illesztések, akárcsak a megfelelő funkcióik, az összevonás és az összefűzés, sokkal többet kínálnak, mint egy egyszerű összekapcsolási funkció. Az opciók és funkciók sorozatának köszönhetően kiválaszthatja az igényeinek megfelelő opciókat.
A Python által kínált rugalmas lehetőségekkel viszonylag egyszerűen rendezheti az eredményül kapott adatkészleteket, az összekapcsolási funkcióval vagy anélkül.